


The Big Five are word vectors
The Big Five are word vectors
The deep connection between language models and personality models

Lexical studies in psychology and Latent Semantic Analysis in computer science were introduced a half century apart to solve different problems and yet are mathematically equivalent. This isn’t a metaphor that works on a certain level of abstraction; the Big Five are dimensions of word vectors.
But first, some background. The Lexical Hypothesis claims that personality structure will be written into the language as the speakers have to describe the most salient attributes of those around them. The beauty of this idea is that, instead of a single person suggesting a model of personality, language records what millions of people implicitly agree to be useful. The psychometrician’s job is to simply identify this structure. This has typically been accomplished by inviting psychology students to rate themselves on lists of adjectives and performing factor analysis on the correlation matrix. Back in 1933, LL Thurstone administered a survey of 60 adjectives to 1300 people. In his seminal The Vectors of Mind, he reports that “five factors are sufficient” to explain the data. In subsequent decades, such studies, more or less, resulted in five principal components: Agreeableness, Extroversion, Conscientiousness, Neuroticism, and Openness/Intellect. (For an excellent treatment of the subject, see Lexical Foundations of the Big Five.)
Latent Semantic Analysis was introduced as an information retrieval technique in 1988. Words can be represented as vectors and documents or sentences can be represented as the mean of their word vectors. If you want to search a large database (e.g., Wikipedia), keywords for each page can only get you so far. One way to get around this is to represent both documents (wiki articles) and queries (search terms) as the mean of their word vectors. Finding relevant documents can now be accomplished with a simple dot product. (In this post, I treat LSA and word vectors as synonymous. There are other ways to vectorize language and, more specifically, make word vectors, but those are beyond the scope for now.)
Despite their different uses and history, the steps are the same:
Collect a word x document count matrix
Nonlinear transformation
Matrix decomposition
Rotation (Optional)
The result is a set of word vectors that succinctly describe each word. These can be used for a host of downstream tasks, from sentiment analysis to narcissism prediction from student essays. In the case of personality adjectives, the dimensions of the word vectors were analyzed, named, and debated for decades. What follows is a discussion of the differences in each step.
Count matrix. LSA usually involves a large number of varied documents (eg. millions of Amazon product reviews). These are transformed to word x doc matrix by counting how often each word appears in each doc. In psychology, a document is the words a subject agrees describe them. This extends to Likert scales as well. If someone says a word describes them 5/7, then simply repeat the word five times in the document.
Nonlinear Transform. Lexical studies often ipsatize the data (z score along the subject axis) and then perform a Pearson correlation. Thurstone used an archaic tetrarch correlation in his study. In LSA, the most common transform is TF-IDF, followed by a logarithm. This ensures the matrix is not dominated by common terms. Often, the transform results in a word x word affinity matrix (eg. correlation matrix). This step is practically very important but not all that theoretical. The transform to pick is the one that gives you a reasonable result in the end.
Matrix Decomposition. There are many methods of matrix decomposition. Some, such as PCA, require a square matrix. Others are robust to missing data. With personality data, the choice doesn’t matter much; the results are very similar. General word vectors require ~300 dimensions to represent a word’s meaning, part of speech, slangness, and much else that gives language texture. As surveys are designed to hold much of that constant, only ~5 dimensions are needed. Thurstone justified his choice of five by looking at the reconstruction error which he reports as a histogram. Later psychologists justified 5 by the reconstruction error (measured with eigenvalues), as well as considering interpretability and reproducibility.

Rotation. Have you ever heard of component over-extraction? It’s not a story the psychologists would tell you. It’s when a researcher extracts too many Principal Components and then rotates variance from the earlier, valid PCs onto the later marginal PCs. This is what happened with the Big Five, believe it or not! What is now Agreeableness was once a much more robust and theoretically satisfying ‘Socialization’ factor, which was spread out over PCs 3-5 to make Conscientiousness, Neuroticism, and Openness. Rotation can be justified to produce interpretable factors. But if you ever find yourself rotating then arguing about the correct number of factors, check yourself!
The Big Three from word vectors
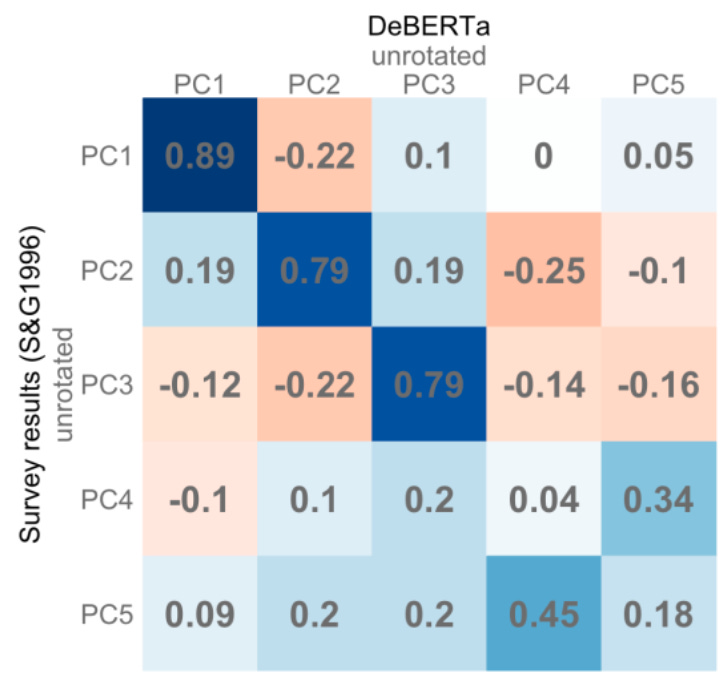
I started my PhD predicting Big Five traits from Facebook statuses. After reading how the personality sausage was made I realized the project used word vectors (of Facebook statuses) to predict noisy approximations of where individuals lived in Big Five space, which was originally defined by word vectors. It seemed more interesting to cut to the chase and learn something fundamental about personality from word vectors. (Also, the dataset I was using became toxic after Cambridge Analytica.) The rest of my PhD was working to constrain word vectors in order to reproduce the Big Five. This involved using transformers rather than LSA (more on that in future posts). The resulting correlation between factors from word vectors (DeBERTa) vs surveys is below. As you can see, there is a very close agreement for the first three factors. Where the results diverge, it’s not clear which method is in error. Maybe surveys are right, and all the correlations will go to 1 when we get GPT-5. Maybe surveys are just biased and noisy, and too many PCs were extracted. Maybe they are measuring different things, and we need to refine our interpretation of both. At any rate it’s not obvious to me that surveys should be considered the gold standard between the two. The Lexical Hypothesis is about language structure, after all, and psychology is the only field that uses surveys to analyze natural language.
Conclusion
Thurstone pioneered methods in statistics and linear algebra to probe the Lexical Hypothesis in the 30s. It is remarkable that he developed a way to represent words that was later rediscovered for information retrieval, which now powers the information age. Computation forced Thurstone to flatten the rich landscape of language to survey responses. In the past 30 years NLP has experienced multiple revolutions. If Thurstone invented a telescope with which to view language structure, we now have Hubble. Many insights await!
Hi I know I'm late, but I'm very interested in this and had a question: Do you know of any studies that a dynamic approach to this topic -- i.e., attempt to trace the change of personality components over time? I was inspired by this piece (https://arxiv.org/pdf/1711.08412.pdf) that looked at stereotypes of women and minorities using the Google Books corpus. I'm interested in the extent to which gender differences in the big 5 hold up historically, which of course raises the question about whether the entire construct holds up historically. I have strong priors that it does NOT, but I can be convinced. Thanks for your time.
I should probably write a blog post somewhere on this, but it really doesn't surprise me that these are vectors. I think what we call "personality" is just emotional responses to common situations.
In Plutchik's Wheel of Emotions model there are 8 emotions that can be split into 4 pillars.
Prediction👁️: Anticipation and Surprise
Threat🗡️: Anger (Dominion) and Fear (Submission)
Morality⚖️: Respect and Disgust
Affect😂: Joy and Sadness
From a biological perspective there is only really "the self" and the environment "the world". Personality is our emotional interactions between those two.
Openness/Intellect: Surprise between the Self and the World
Openness: "do you find surprise in the world unthreatening".
Intellect: "does surprise in the world produce joy".
Extroversion: Joy and Anger between the Self and the World
Enthusiasm is "do people bring you joy"
Assertiveness is "when people threaten you do you dominate or submit"
Conscientiousness (tribe relations): Morality between the Self and the World Industriousness/Orderliness is "will coworkers find you respectable (Morality)"
Agreeableness (Affect and the World): Sadness and Fear in the World and the Self's response. Compassion/Politeness: When people are sad/afraid does that make you sad/afraid?
Neuroticism: Are you more governed by the Carrots or the Sticks of emotions? High Neuroticism means you react strongly to the sticks.